
Python Lists: A closer look, part 8
MP #15: Be careful passing lists as arguments

Note: The previous post in this series discussed Python’s sets. The next post focuses on why you shouldn’t try to modify a list inside a for loop.
For the most part, lists have fairly predictable behavior. When you add something to a list, it will be there later in your program’s execution when you need to use it. If you remove an item, you won’t find it in the list at a later time. However, there are a few situations where the behavior associated with a list can be surprising. Knowing about these situations will help you avoid unwanted behavior, and address it when it does pop up in your programs.
In this post, we’ll take a closer look at what happens when you pass a list as an argument to a function.
Passing lists to functions
When a function receives a list as an argument, the function has direct access to the contents of that list. If a function modifies a list that it receives, those changes will affect the list that was passed to the function as well.
Consider a function that validates a series of requests. The function takes in a list of raw requests, and a list where it can store valid requests. It empties the list of raw requests, and appends any valid requests to the list of validated requests:
# process_requests.py
def validate_requests(raw_requests, valid_requests):
"""Validate a sequence of requests."""
while raw_requests:
request = raw_requests.pop(0)
if "bad" not in request:
valid_requests.append(request)The code you see here isn’t the best way that this function could be implemented; imagine this is from a third-party library that you can’t currently change, or another team’s code that you can’t immediately change. You have to send your data to this function if you want to validate your requests.
Now let’s use this function. We’ll make a list containing some raw requests, and an empty list of valid requests. These variable names each begin with my_, so we can distinguish variables that are used in the main program file from variables that are used inside the function. Then we’ll call validate_requests(), and print the lists to see how they’ve changed:
def validate_requests(raw_requests, valid_requests):
...
# Make a list of raw requests, and a list to hold valid requests.
my_raw_requests = [
'request_0', 'request_1_bad', 'request_2',
'request_3_bad', 'request_4_bad', 'request_5',
'request_6', 'request_7_bad', 'request_8',
'request_9_bad', 'request_10', 'request_11_bad'
]
my_valid_requests = []
# Validate requests, and see what has changed.
validate_requests(my_raw_requests, my_valid_requests)
print(f"My raw requests: {my_raw_requests}")
print(f"My valid requests: {my_valid_requests}")Here’s the output:
My raw requests: []
My valid requests: ['request_0', 'request_2', ..., 'request_10']Notice that the list my_raw_requests is empty after calling validate_requests(). The list my_valid_requests only contains the requests without the word 'bad'.
By default, passing a list to a function gives the function access to the contents of the list. The function doesn’t just get a copy of the list; any changes made to the list in the function affect the original list as well. Since validate_requests() uses pop(), my_raw_requests is emptied out after the function has finished running.
Visualizing list objects
A great tool for seeing what’s happening in a program like this is Python Tutor. This tool generates a visual representation of the data structures that a program has, and shows how the different functions in a program access those data structures. Using Python Tutor, you can step through your program’s execution one step at a time and see how data objects are created and modified throughout the course of the program’s execution.1
Here’s how Python Tutor represents the data in this program, after creating the two lists my_raw_requests and my_valid_requests:

my_raw_requests initially contains both good and bad requests, while my_valid_requests is empty.The main thing to notice here is that my_raw_requests points to a list containing a number of items, including good and bad requests. The list my_valid_requests is empty at this point.
Here’s what things look like when execution reaches the beginning of validate_requests():
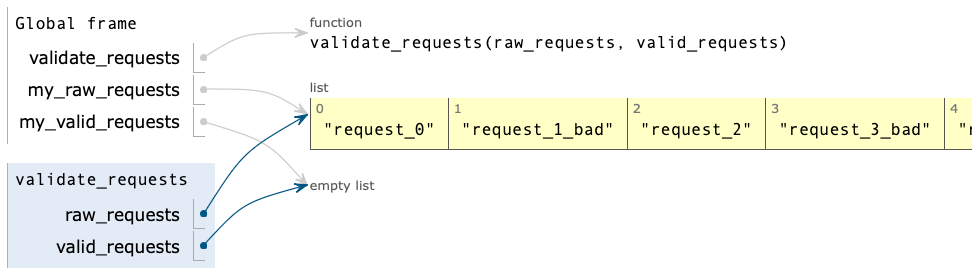
raw_requests, in validate_requests(), points to the same data that my_raw_requests points to.This is really important. Notice that the name my_raw_requests from the body of the program, and raw_requests from inside validate_requests() both point to the same list object. At this point in the program’s execution, they’re just different names for the same sequence of data.
After the loop has finished running, just before the program exits validate_requests(), here’s how things look:

my_raw_requests is now empty. Both my_valid_requests and valid_requests point to a list containing only valid requests.All of the requests have been popped from the original list my_raw_requests. The valid requests have all been appended to valid_requests, which is the same data structure as my_valid_requests. The bad requests no longer exist.
To complete this set of visualizations, here’s what things look like when the program has finished running:
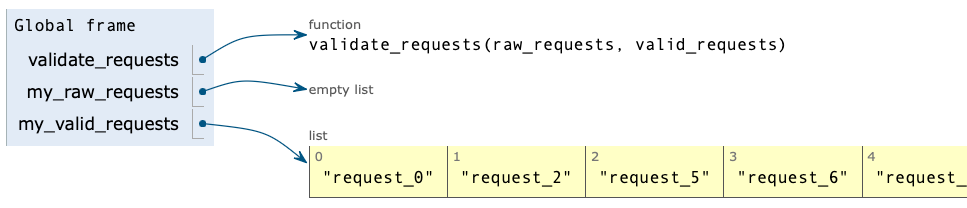
This matches what we saw in the program’s actual output. If you haven’t done so already, take a moment to step through this program on Python Tutor yourself.
Preventing a function from modifying a list
The behavior shown so far can be perfectly reasonable in many applications. This is the default behavior for handling lists that have been passed to functions because it’s relatively efficient. The program only ever used one copy of the list of raw requests; if this was a particularly long list, copying it unnecessarily would have consumed a lot more memory. Any programs that pass large lists to functions would run much slower than they currently do.
But what if you want to protect a list from being modified by a function? For example, what if you want to preserve the list of raw requests while getting a list of valid requests? Maybe after validating the good requests you’ll need to send the list of raw requests to a logging function, while passing the valid requests to a function that executes the requests.
The good news is this is really simple to do. We can do it by changing one line in the previous example:
# process_requests_protected.py
def validate_requests(raw_requests, valid_requests):
...
# Make a list of raw requests, and a list to hold valid requests.
my_raw_requests = [
...
]
my_valid_requests = []
# Validate requests, and see what has changed.
validate_requests(my_raw_requests[:], my_valid_requests)
print(f"My raw requests: {my_raw_requests}")
print(f"My valid requests: {my_valid_requests}")The only difference here is that instead of passing my_raw_requests to validate_requests(), we pass a copy of my_raw_requests.2
Here’s what the program’s execution looks like at the start of validate_requests(), with this one change:

raw_requests, in validate_requests(), points to a copy of the original data from my_raw_requests.Now there are two copies of the list of raw requests. The function validate_requests() no longer has access to the original data in my_raw_requests. Instead, it’s given its own copy of that data to work with.
Here’s what things look like after the program has finished running:

my_raw_requests.We have a list of valid requests, just like in the original program. But now we still have the original list of raw requests. We can do any additional processing we want on those raw requests, while also being able to start working with the refined list of valid requests.
Conclusions
There are a number of takeaways from this discussion. First, if you’re passing a list to a function that you don’t have control over, make sure you know whether the function will modify the list that you’re working with. If it does and you’re okay with how if affects your list, go ahead and pass your actual list to the function. If the function modifies the lists it receives and you don’t want those changes to affect your list, pass the function a copy of your list.
If you're writing a function that receives a list, make sure you are clear about whether the function can modify the list at all. Include a statement in the function’s docstring about how the function may affect the lists it receives.3 If you don't want your function to modify a list that it receives, consider making a copy of the list at the beginning of the function, and only work with the copied data in the body of the function. You can also consider returning the list that the caller needs, rather than directly modifying the original list.
Real-world scenarios will often make it clear what a function should do in regards to lists, and whether a function call should pass a list or a copy of a list. For example, in a situation where you have direct access to all of the code in a project, you may want to let functions modify lists in order to develop an efficient workflow. If you don’t have access to all of the code, you may want to pass copies of your lists to ensure no unwanted changes happen to them.
As long as you know how lists interact with functions, you can make the right decisions, and write the correct code, for your given situation.
Resources
You can find the code files from this post in the mostly_python GitHub repository.
Further exploration
1. Optimizing process_requests.py
Using generate_requests.py to build a longer list of raw requests, increase the number of requests in my_raw_requests to the point that the program takes 10-20s to run. How much more efficient can you make the program? Use profiling to measure the impact of your optimization efforts.
2. Documenting validate_requests()
Write a more complete docstring for validate_requests(), using the guidelines in PEP 257. If you optimized process_requests.py, write a complete docstring for your version of validate_requests(). Call help(validate_requests), and make sure your docstring makes sense in that context.
Also note the slider, which lets you quickly get to the part of your program’s execution that you want to focus on. You can then use the <Prev and Next> buttons to move one step at a time through your program’s execution.
In case this syntax is unclear, this is a slice that generates a full copy of the list. A typical slice looks like raw_requests[start_index:end_index]. Omitting the first index in the slice defaults to 0, and omitting the second index defaults to the last item in the list. So the syntax raw_requests[:] says, “Please give me a slice of the list from the first item to the last item.” This results in a full copy of the list.
If you’re unclear about what a good docstring should look like, see PEP 257 - Docstring Conventions, especially the part about multiline docstrings. Another good resource to look at is the pandas docstring guide. The main idea of a docstring is that someone can run help(your_function_name) and see a description of exactly what the function does, and how to use the function, without having to read the function’s source code.
Most of the docstrings you see in Mostly Python are shorter than what you’d see in real-world code, because they’d take up a lot of space in each post. I look forward to writing a full discussion at some point about how to document your code for your own use, and for others who may work with the code that you write.